
머신 러닝의 한 분류인 Supervised Learning은 크게 Regression 또는 Classification으로 나뉜다. Computer Vision에서 classification 분류는 흔한 일이기에 정리한다.
Scikit-Learn의 SGDClassifier를 이용하여 MNIST 데이터 셋의 숫자 7을 분류하는 분류기를 구현하던 도중, 숫자 7은 어차피 전체 비율의 10 % 밖에 없기에 항상 false로 예측하더라도 예측률이 적어도 90%는 찍게 된다. 여기까지의 과정은 다음 코드에 담겨있다. 개발 환경은 Google Colab 이다.
1. import 데이터
from sklearn.datasets import fetch_openml
mnist = fetch_openml('mnist_784', as_frame=False)
X, y = mnist.data, mnist.target
2. 데이터 그래프 그려보기
import matplotlib.pyplot as plt
def plot_digit(image_data):
image = image_data.reshape(28, 28)
plt.imshow(image, cmap="binary") # grayscale
plt.axis("off")
some_digit = X[0]
plot_digit(some_digit)
plt.show()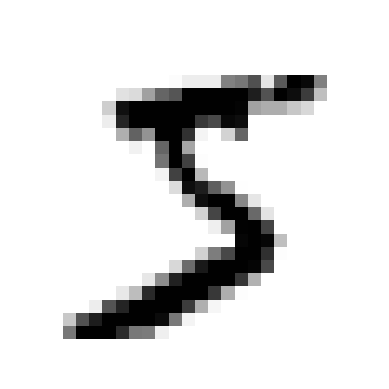
3. train, test 데이터 셋 나누기 , 숫자 7 데이터 셋 준비하기
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]
y_train_7 = y_train == '7'
y_test_7 = y_test == '7'
4. scikit-Learn의 SGDClassifier 사용하기
from sklearn.linear_model import SGDClassifier
sgd_clf = SGDClassifier(random_state=19)
sgd_clf.fit(X_train, y_train_7)
sgd_clf.predict([X_test[0]])
5. 훈련된 모델 K-Fold Cross-Validation으로 평가하기
# k-fold cross-validation with three folds
from sklearn.model_selection import cross_val_score
cross_val_score(sgd_clf, X_train, y_train_7, cv=3, scoring="accuracy")result : array([0.9808, 0.9745, 0.98 ])
cross-validation score가 높을 수 있지만 문제는 Scikit-Learn의 DummyClassifier를 사용해도 높다는 것이다.
이럴 때는 Confusion Matrix를 사용하는 것이 좋다.
다행히 Scikit-Learn 라이브러리가 제공하며 단 4줄로 구현 가능하다.
from sklearn.model_selection import cross_val_predict
y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_7, cv=3)
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_train_7, y_train_pred)cm 을 출력해보면 array([[53077, 658], [ 636, 5629]]) 이 나온다. 각 행(row)는 실제 클래스이고, 각 열(column)은 예측한 클래스이다. 53077 개의 사진은 실제로 7이 아니며, 7이 아니라고 판별 되었고, 658 개의 사진은 7이 아니지만 7로 잘못 예측되었고, 636 개의 사진은 7이 맞지만 7 이 아니라고 잘못 예측되었고, 5629 개의 사진은 7 이면서 7로 잘 예측되었다. 순서대로 true negative, false positive, false negative, true positive. 가장 이상적인 confusion matrix는 false positive와 false negative가 0 이어야 한다.
Confusion Matrix를 볼 때 중요한 2 가지 지수는 precision, recall 이다.
Precision = (True Positive) / (True Positive + False Positive)
Precision 지수를 보면 항상 Negative로 판별하게 되면 단 한 개의 True Positive 만 있어도 100 % 가 되게 된다. 따라서 이 지수는 Recall 이라는 지수와 함께 쓰인다. (a.k.a. Sensitivity, True Positive Rate (TRR) ).
Recall = (True Positive) / (True Positive + False Negative)
from sklearn.metrics import precision_score, recall_score
precision_score(y_train_7, y_train_pred)0.895339589629394
recall_score(y_train_7, y_train_pred)0.8984836392657621
이렇게 보니, 그렇게 좋은 정확도를 보이는 것 같지는 않다.
Precision, Recall을 따로 보지 않고 합쳐서 F1 Score 로 보기도 한다.

F1 Score는 Harmornic Mean이라고도 불린다. 평균을 구하는 듯 보이지만 일반적인 평균은 모든 값을 평등하게 더하고 나눈다. 하지만 F1 Score의 Harmornic Mean은 낮은 값의 영향력을 더 키우기 때문에 Recall 과 Precision 모두 높아야 값이 높아진다. 다행히 Scikit-Learn은 F1 Score도 지원한다.
from sklearn.metrics import f1_score
f1_score(y_train_7, y_train_pred)
F1 Score는 Precision, Recall 모두 높은 Confusion Matrix에 대해 높은 값이 나오지만, 모든 상황에 적용되지는 않는다. 예를 들어, 어린이에게 부적절한 영상을 필터링하는 작업은 차라리 좋은 영상을 필터링하더라도 (낮은 recall), 좋은 영상만 어린이에게 보여지기(높은 precision)를 원한다.
그래도 둘 다 높을 때가 좋겠지만 아쉽게도 Underfitting, Overfitting 처럼 Precision, Recall 에도 Trade-Off가 존재한다.