
이 글은 논문에 대한 번역글이 아니며, 중요 부분과 요약 부분을 다룬 글이다. 대학 학부생의 수준이니 높은 신뢰성은 보장되지 못한다.
Summary of Paper
이 글이 나왔을 시점인 2015년 경에 2.5D depth sensor가 생겼다. 2D 이미지지만, 2.5D의 depth (깊이)를 빨간색이 먼쪽, 파란색이 가까운쪽을 의미하게 색칠하여 보이게 한다. 이 글에서는 2.5D depth map에서 3D volume을 얻는 것과 2.5D depth map image가 가리키는 사물의 category recognition 분류를 목표로 한다. 한 개의 2.5D depth map이 아닌 target 3D object를 카메라의 여러 각도, 위치로 찍은 여러 개의 2.5D depth map image로 3D volume을 만든다 어떻게 만들까? 방법은 각 voxel(volume + pixel)이 1 또는 0의 값을갖는 3D voxel grid을 형성하여 대상 object의 모양에 따라 1, 0을 부여하여 만든다. Voxel은 volume + pixel 이기에 부피가 있지만 pixel 과 같이 위치가 부여된다. Training 과정에서 사용한 Dataset은 ModelNet이라는 3D CAD model dataset이다.
이 논문에서 볼 중요한 부분은 1) target object에서 어떻게 여러 개의 2.5D depth map image를 얻을 것인지 2) 여러 개의 2.5D depth map에서 어떻게 3D object을 얻을 것인지 3) 어떤 Model을 사용할 지이다.
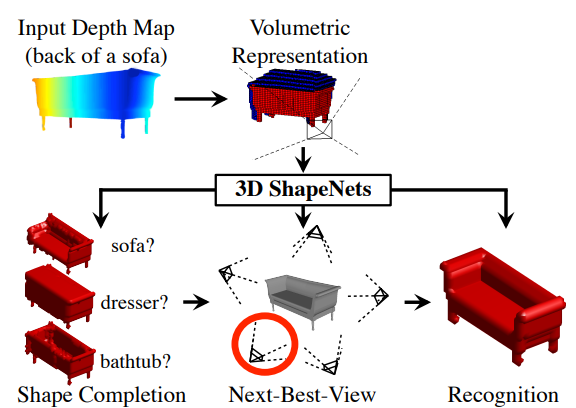
1) target object에서 어떻게 여러 개의 2.5D depth map image를 얻을까?
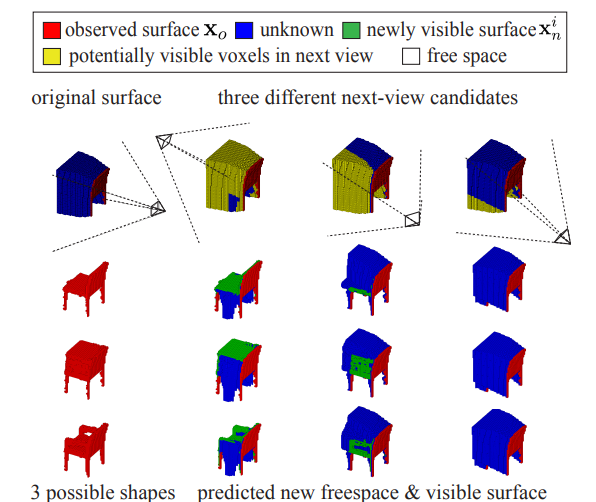
위의 이미지를 보면, 물체를 보는 시점, 즉 depth image(2.5D 생략)를 얻는 카메라의 위치와 각도에 따라서 target object에 대해 얻을 수 있는 정보가 다르다. 여러 장의 사진이 필요함은 알 수 있지만 가장 효율적으로 사진을 얻기 위해서는 카메라의 위치를 바꿀 때마다 얻는 정보가 최대여야 한다. 논문에서는 Next-Best-View Prediction으로 불리며 View Planning algorithm이라 부른다. Voxel data를 x, object category label을 y라고 하면, P(y | x) 를 통해 x의 voxel data를 가질 때, category가 y로 분류될 조건부 확률을 구할 수 있다. Object recognition uncertainty는 entropy로 주어지며,
H = H (p(y|xo = xo)) = − p(y = k|xo = xo) · log( p(y = k|xo = xo) ) , (k = 1 ~ K) 까지 합
1~K는 y가 될 수 있는 category 값들을 정수로 표현한 값이다. 카메라의 위치를 옮겼을 때 새로 발견되는 voxel을 x_n으로 하면, recognition uncertainty는 아래와 같이 수정된다.
H_i = p(x_n | xo = xo) · H(y|x_n , xo = xo) , (모든 x_n 의 합)
Information Theory 에 따르면 H - H_i 만큼의 entropy 변화 (≥ 0)는 y와 x_n가 갖는 공통적인 information이므로 recognition uncertainty는 언제나 감소한다. 앞선 2개의 공식을 통해 y와 x_n이 갖는 공통적인 information을 최대화하는 알고리즘은 아래와 같다.
V∗ = arg max (H - H_i) 하는 V_i. V_i를 카메라 위치의 후보들이 모여있는 집합의 원소라고 했을 때, H - H_i를 최대화 하는 V_i를 찾는 알고리즘
2) 여러 개의 2.5D depth map에서 어떻게 3D object을 얻을 것인지
1) 에서 다룬 바와 같이 2.5D depth map은 얻을 수 있다. 그렇다면 2.5D depth map에서 어떻게 3D object을 얻을까? 이 논문에서 제시하는 모델은 hidden layer에 pooling layer가 없다. pooling layer가 특징을 잘 대표할 수 있지만 논문에서는 object recognition uncertainty를 높일 가능성으로 인해 사용하지 않는다.
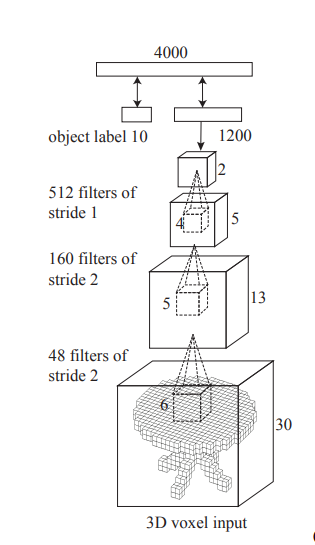
위의 이미지를 보면 input이 3D voxel input이다. 어라? 이상하다. 전 문단에서 input은 2.5D depth map image여서 2D여야 한다. 바로 이 부분이 전에 나온 논문과 차별되는 부분이며, 특별한 부분이다. 다른 논문들은 2.5D depth map image를 사용하긴 해도 2D로 사용하지만 이 논문은 3D로 바꾼다. 또한, input은 사실 24 x 24 x 24이지만 zero-padding을 3만큼 양쪽에 모든 방향으로 넣어서 30 x 30 x 30 으로 바뀌었다. pooling layer 대신에 filter size와 stride를 조절해서 channel의 크기를 작게 만든다. 결국 마지막에는 Fully-Connected Layer와 K softmax를 통해 object category label을 지정한다.
3) 어떤 모델을 사용할 것인지
이미 Convolutional Network를 사용함을 알지만 어떤 방식으로 진행했는지 보도록 한다. Training할 때 물체의 중력 방향 축을 기준으로 30도씩 돌게 하여 data augmentation을 진행하였다. 또한, 3D Voxel Input은 0 과 1만 가질 수 있으며, 모델을 보는 카메라의 시점에 따라 2.5D depth map을 통하여 30 x 30 x 30 공간 안에 각 voxel들에 0 또는 1을 부여한다. 실제로 3D CAD model에만 성능이 좋을 뿐만이 아니라, NYU dataset에 있는 실생활의 object에도 성능이 좋아서 어느 정도 증명이 됐다.
끝!
'Computer Science > AI' 카테고리의 다른 글
| Classification 분류기 분석. Cross-Validation 대신에 Confusion Matrix 사용하기. (1) | 2023.12.05 |
|---|---|
| [AI 이론] 인공지능 입문 이론 한 번에 정리하기! (0) | 2023.04.10 |
| [AI 이론] 인공지능과 확률 정복하기 (Generative Model, Discriminative Model, Bayes Theorem) (0) | 2023.04.04 |